













Wysokodostępny loadbalancer czyli HAProxy z Keepalived
|

W tym artykule przeprowadzę was przez proces instalacji i konfiguracji wysokodostępnego loadbalancera. Ale zanim zaczniemy mamy do rozszyfrowania trochę nazw i pojęć, które dla osoby początkującej mogą być jeszcze nieznane.
Zacznijmy przede wszystkim od tego co chcemy osiągnąć. I tu nie musimy specjalnie puszczać wodzy fantazji: przy obecnych aplikacjach webowych zupełnie naturalną potrzebą jest rozdzielenie ruchu na więcej niż jedną maszynę. Załóżmy, że mamy jakąś aplikację, która już z ruchem nie daje sobie rady na jednym serwerze (np. jest już całkiem spora i droga instancja VPS) i przychodzi czas aby rozdzielić pewne jej usługi na kilka serwerów. Niech to będzie serwer www (nginx, apache, obojętnie). I tu napotykamy pierwszy problem: jak ten strumień ruchu rozdzielić na więcej serwerów? Odpowiedzią jest właśnie loadbalancer czyli usługa, która wg. zadanych kryteriów jest w stanie żonglować ruchem pomiędzy maszynami. Jest wiele możliwości wyboru loadbalancera (choćby sprzętowy lub często w usługach typu cloud jako osobna usługa), choćby popularny serwer www Nginx ma taką możliwość. Ale my zajmiemy się jednym z najbardziej popularnych softów w tej działce czyli HAProxy.
OK, mamy nasze serwery, mamy loadbalancera z przodu ale zaraz, zaraz, przecież jak padnie mi ten loadbalancer to będę miał zero pożytku z tych wielu serwerów www. To przecież klasyczny SPoF („single point of failure” - „pojedynczy punkt awarii”). A gdzie tu ta tytułowa wysoka dostępność? I tutaj dochodzimy do drugiego składnika naszej układanki czyli do Keepalived. W czym nam on pomoże? Zdublujemy instancje z loadbalancerem czyli będziemy mieli dwa loadbalancery, a dzięki Keepalived będziemy mogli przełączać się między nimi w razie awarii jednego z nich. Fajne? Tak 😉
Co potrzebujemy?
Do wykonania naszej układanki będziemy potrzebować:
- dwie instancje pod loadbalancera (HAProxy)
- lb1.webmastah.dev - 192.168.0.100
- lb2.webmastah.dev - 192.168.0.101
- dwie instancje pod serwer www (nginx)
- web1.webmastah.dev - 192.168.0.102
- web2.webmastah.dev - 192.168.0.103
-
- wirtualny IP (zwany też floating IP, zapytaj o to swojego usługodawcy VPS), który będzie dopinany do jednej z instancji loadbalancera - 192.168.0.99
Całośc ostatecznie będzie tak wyglądała:
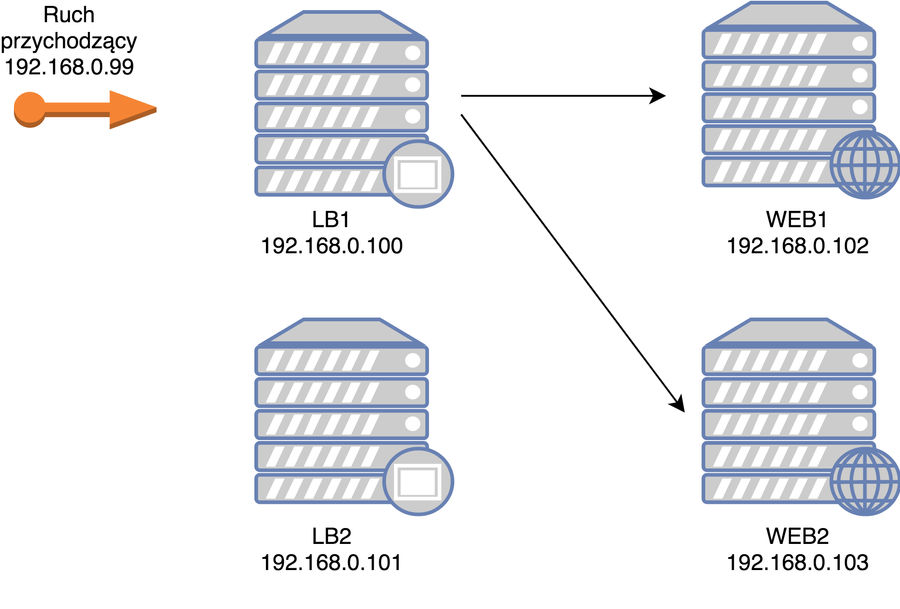
schemat naszego środowiska
Serwery WEB
Zacznijmy od najprostszej rzeczy czyli przygotowania serwerów web. Tutaj nie ma żadnej filozofii, po prostu instalujemy gołego nginxa na obu serwerach. Do defaultowej strony wyświetlanej przez nginx możecie dopisać „WEB 1” / „WEB 2” aby ułatwić sobie testy - zorientowanie się, który serwer w danej chwili będzie odpowiadał na żądanie.
Serwery LB
Instalujemy HAProxy i przechodzimy do edycji /etc/haproxy/haproxy.cfg
Kluczowe są dwie sekcje tej konfiguracji: ustawienia frontendu i backendu. Przez frontend rozumiemy ruch, który wchodzi do HAProxy, a przez backend rozumiemy ruch, który zostaje wypychany na dane serwery końcowe.
log global
mode tcp
option tcplog
frontend www
bind 192.168.0.99:80
default_backend nginx
backend nginx
balance roundrobin
mode tcp
server web1 192.168.0.102:80 check
server web2 192.168.0.103:80 check
W sekcji frontend ustawiamy nasze główne IP gdzie będzie ruch przychodzący i które to IP będziemy w razie potrzeby przepinali między głównym i zapasowym loadbalancerem. W sekcji backend wymieniamy nasze serwery WEB.
Konfiguracja HAProxy to temat na zupełnie inny artykuł, powyżej skupiłem się tylko na części niezbędnej do wykonania tego poradnika, nie mniej warto dodać jeszcze, że w sekcji global możemy dopisać:
option dontlog-normal
co spowoduje logowanie wyłącznie błędów, oraz:
option log-health-checks
co pomoże wyłapać (zalogować) problemy ze stabilnością (kompleksowe rozwinięcie tego tematu znajdziecie tutaj: Performing Health Checks).
Restartujemy HAProxy i sprawdzamy czy działa i czy wszystko jest OK w jego logach. Od tej chwili odpalając nasze główne IP powinniśmy zobaczyć na zmianę strony serwowane przez serwery WEB. Jeżeli wcześniej oznaczyliśmy sobie na każdym nginxie jaki to jest nr serwera to teraz przy wywoływaniu strony możemy zobaczyć jak są one losowo (nie muszą być losowo, są różne mechanizmy rozdzielania ruchu ale to już oddzielny temat) odpytywane.
Żeby HAProxy mogło przypisać się do naszego głównego IP na drugiej maszynie (czyli tej która w danej chwili jest zapasowa) potrzebujemy zezwolić na taką akcję poprzez dodanie net.ipv4.ip_nonlocal_bind=1 w /etc/sysctl.conf (po dodaniu wpisu przeładuj sysctl -p).
Na tym etapie warto też upewnić się, że HAProxy uruchamia się samo po restarcie systemu. Wykonanie tego jest zależne od waszego systemu, dla Debiana czy Ubuntu będzie to edycja /etc/default/haproxy i dodanie ENABLED=1, dla CentOSa 6 chkconfig haproxy on, CentOSa 7 systemctl enable haproxy.
Keepalived
No dobrze, loadbalancer już mamy, w takim razie zostało nam powtórzenie w/w czynności aby w identyczny sposób skonfigurować LB2. I teraz możemy przejść do mechanizmu, który w razie problemów z LB1 przestawi na obsługę loadbalancera z serwera LB2.
Na obu serwerach zabieramy się do konfiguracji Keepalived. Edytujemy /etc/keepalived/keepalived.conf, na LB1 (MASTER) wygląda to tak:
vrrp_script chk_haproxy {
script "killall -0 haproxy" # verify the pid existance
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}
vrrp_instance VI_1 {
interface eth0 # interface to monitor
state MASTER
virtual_router_id 51 # Assign one ID for this route
priority 101 # 101 on master, 100 on backup
virtual_ipaddress {
192.168.0.99 # the virtual IP
}
track_script {
chk_haproxy
}
}
z kolei na LB2 (SLAVE) modyfikujemy dwie zmienne: priority i state:
vrrp_script chk_haproxy {
script "killall -0 haproxy" # verify the pid existance
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}
vrrp_instance VI_1 {
interface eth0 # interface to monitor
state BACKUP
virtual_router_id 51 # Assign one ID for this route
priority 100 # 101 on master, 100 on backup
virtual_ipaddress {
192.168.0.99 # the virtual IP
}
track_script {
chk_haproxy
}
}
Jak to działa? To proste: demony Keepalived sprawdzają wzajemnie czy druga strona jeszcze „żyje”. W przypadku kiedy server SLAVE zorientuje się, że MASTER nie odpowiada to przypisuje nasze główne IP na swój serwer przejmując do siebie cały ruch. Oczywiście LB1 i LB2 muszą być w sieci gdzie działa multicast.
Sprawdźmy to: zatrzymajmy HAProxy na LB1 i po paru sekundach nasz ruch powinien już odbywać się przez LB2. MAGIA!
W takiej sytuacji nasz pierwotny diagram zmienia się na:
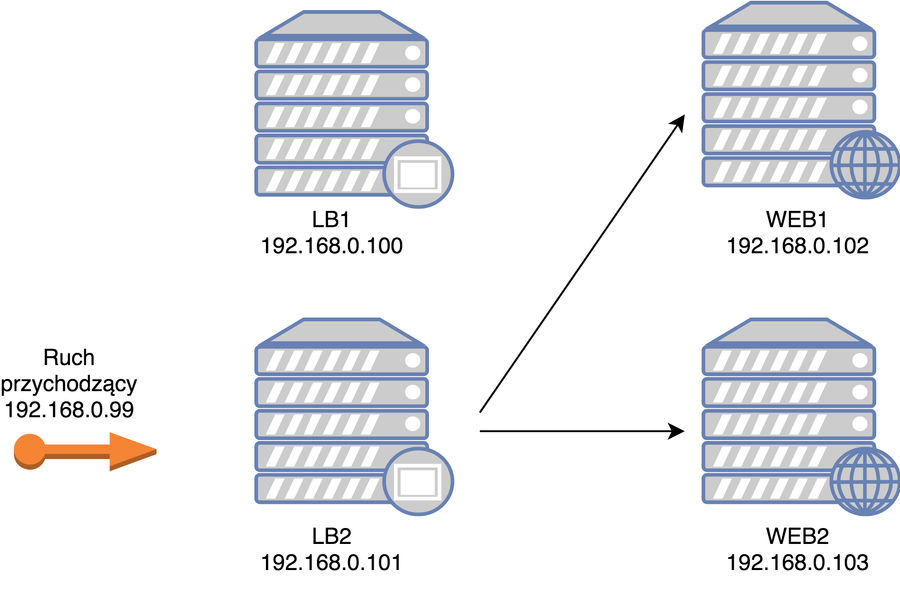
wirtualny IP został przypisany do zapasowego loadbalancera
Komunikację demonów Keepalived możesz podejrzeć poprzez:
tcpdump -i <interfejs do którego podpięty jest Keepalived> vrrp -c 10 -v
Podsumowanie
Jak widzicie w dosyć prosty sposób w góra godzinę jesteśmy w stanie postawić i skonfigurować wieloserwerowe wysokodostępne środowisko. W obecnych czasach gdzie mamy wysyp usług typu „VPS in cloud” z podstawowym pakietem za $5 jesteśmy w stanie bardzo niskim kosztem uruchomić całkiem nieźle skalowane środowisko produkcyjne. Dorzucając do tego trochę automatyki w konfiguracji i w zestawianiu nowych instancji VPS jesteśmy w stanie za naprawdę małe pieniądze utrzymywać bardzo elastyczne i wydajne środowisko, które wbrew pozorom może starczyć na bardzo, bardzo długi rozwój naszego projektu. To jeszcze nigdy nie było takie proste i takie tanie!
Jeżeli któryś z fragmentów jest potraktowany zbyt ogólnie i sprawia wam problemy to proszę dajcie znać w komentarzach, postaram się rozbudować artykuł.
Myślę też, że ten temat aż prosi się o nakręcenie go w formie LIVE konfiguracji na infrastrukturze jednego z dostawców „VPS w chmurze”: krok po kroku od uruchomienia maszyn, przez instalacje i konfigurację, a kończąc na odpaleniu naszej aplikacji. Kręcić? Zasubskrybuj mój kanał, żeby nie przegapić tego materiału!
Fujitsu GDC Poland zatrudnia specjalistów w pięciu liniach biznesowych: Research & Development i Business Application Services, Remote Infrastructure Management, BPO, Service Management, Service Desk. W Łodzi, Fujitsu zatrudnia również specjalistów do jednostki EMEIA Finance and Supply Chain Services. Firma zaprasza do swojego zespołu osoby zainteresowane karierą w branży IT, osoby ze znajomością języków, programistów, informatyków, administratorów i inżynierów IT oraz specjalistów ze znajomością zagadnień z obszaru księgowości i finansów.
Chcesz kariery #NaSerio? Odwiedź www.TheRealDeal.pl
